Bár a felhasználók többsége jól elvan a távoli szervereken villámgyorsan működő, online felülettel vagy dedikált alkalmazással, internet-kapcsolaton keresztül elérhető AI-csevegőkkel és MI-asszisztensekkel, ezek használata azért rejt magában némi kockázatot, hiszen a legtöbb ilyen szolgáltatás a beszélgetéseket tovább hasznosítja az AI modellek tanítására, ráadásul a szolgáltató maga is hozzáfér a csevegések tartalmához. Üdítő kivétel ez alól a Proton Lumo, amely egy e2e titkosítást használó online AI-csevegő. De ennél is jobban védhetnénk privát szféránkat, ha offline, magán a számítógépen menne végbe a teljes folyamat. Erre is mutattunk már több megoldást is, például a nagyon egyszerűen beüzemelhető LM Studio alkalmazást(Windows, macOS, Linux), illetve szóba került már nálunk az is, hogyan lehet megoldani ezt a dolgot az Ollama nevű parancssori alkalmazással. Ez utóbbi most óriási frissítést kapott, amelynek köszönhetően jelentősen gyorsult vele az AI modellek offline működése, de ami még ennél is szebb: itt a hivatalos Ollama asztali alkalmazás is, amelyben parancssor nélkül, kényelmes felületen cseverészhetünk a letöltött AI modellekkel, amelyek letöltése is sokkal egyszerűbbé vált így.
Ollama asztali alkalmazás használata: offline AI asszisztens, kényelmes felülettel
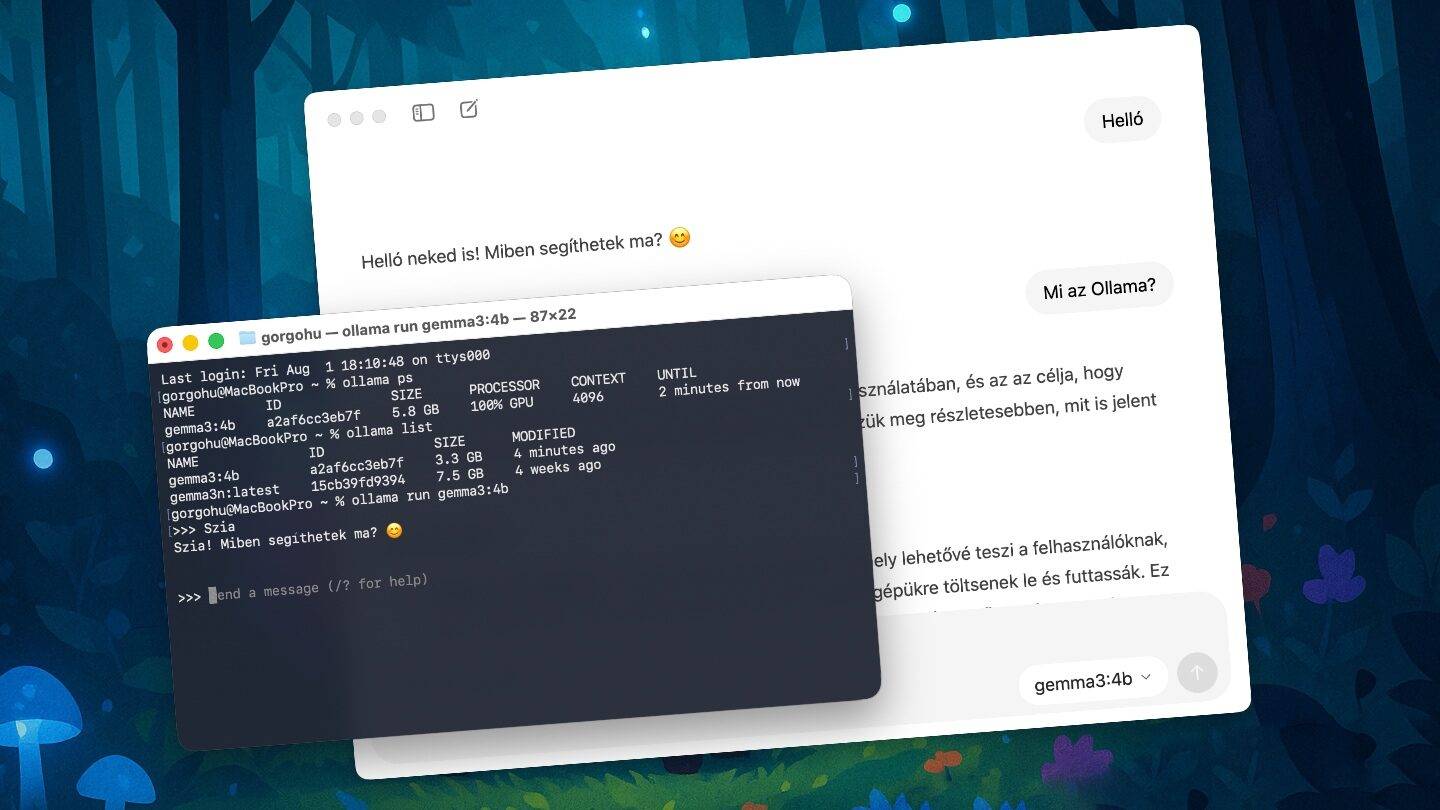
Ha valaki eddig nem ismerte volna, az Ollama egy parancssori alkalmazás, amellyel helyi szinten megoldható a generatív mesterséges intelligencia modellek futtatása, közvetlenül a saját számítógépünkön. Semmi nem hagyja el a gépet, az AI offline válaszolgat a kérdéseinkre. Ezzel a megoldással olyan ingyenes AI modelleket lehet futtatni a gépen, mint a DeepSeek-R1, a Google Gemma 3, a Meta Llama 3, a Microsoft Phi 4 és még megannyi ügyes megoldás. Beüzemelni és kényelmesen használni viszont eddig – lévén csak egy parancssori alkalmazásról beszélünk – nem volt egyszerű. Erről anno itt írtunk részletesebb útmutatót.
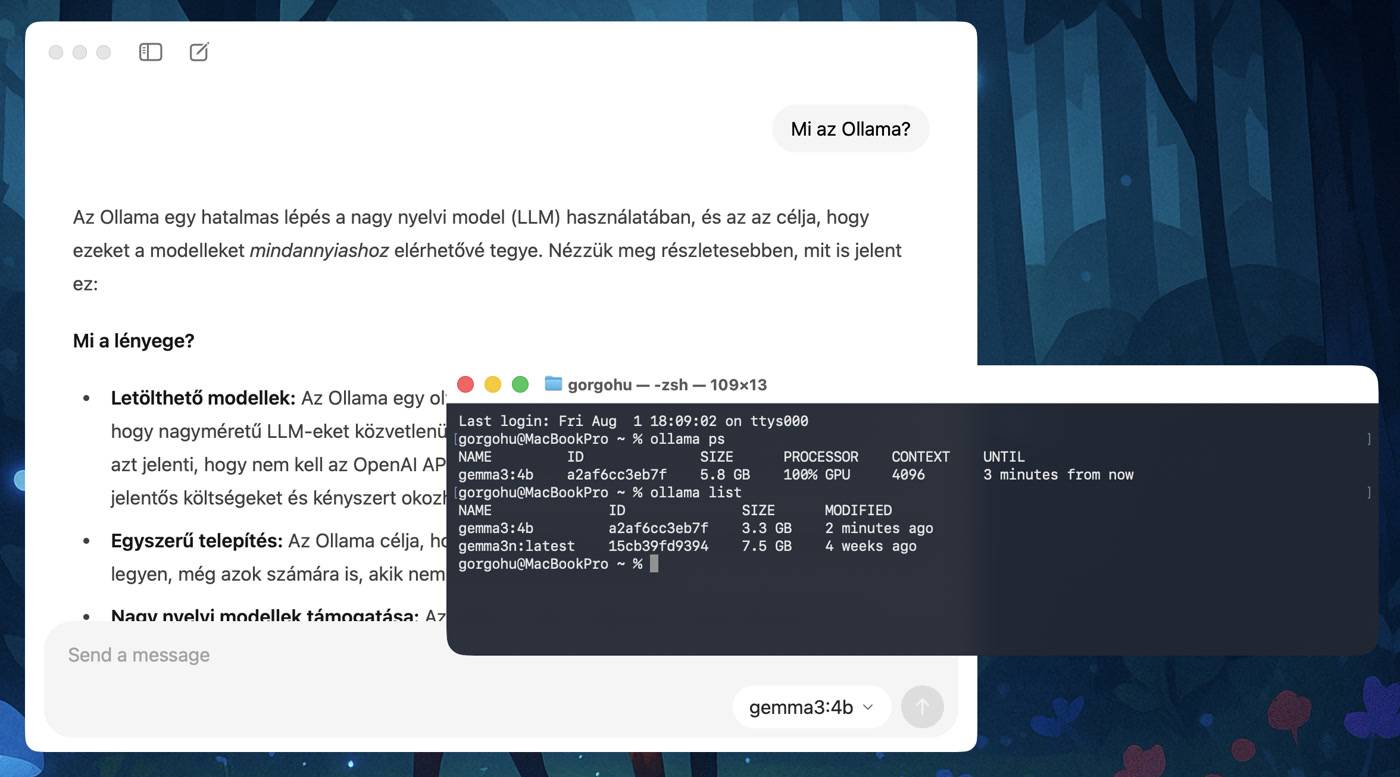
Mostantól viszont változik a helyzet, letölthető ugyanis a készítő oldaláról a legújabb Ollama, amely ugyan még mindig használható parancssori alkalmazásként, s így ugyanazon felhasználási módok is megmaradtak, de egyben lehetővé vált egy hivatalos Ollama asztali alkalmazás használata is. Vagyis az adott rendszernek megfelelő grafikus felülettel (Windows, macOS, Linux) tudjuk használni a telepített offline MI modelleket, pont, ahogy azt mondjuk a ChatGPT, a Perplexity vagy a Copilot kilensei esetében megszokhattuk már. De a lényeg persze nem változott: itt a letöltött modelleket használjuk, offline. Nem kerül ki semmi a gépünkről.
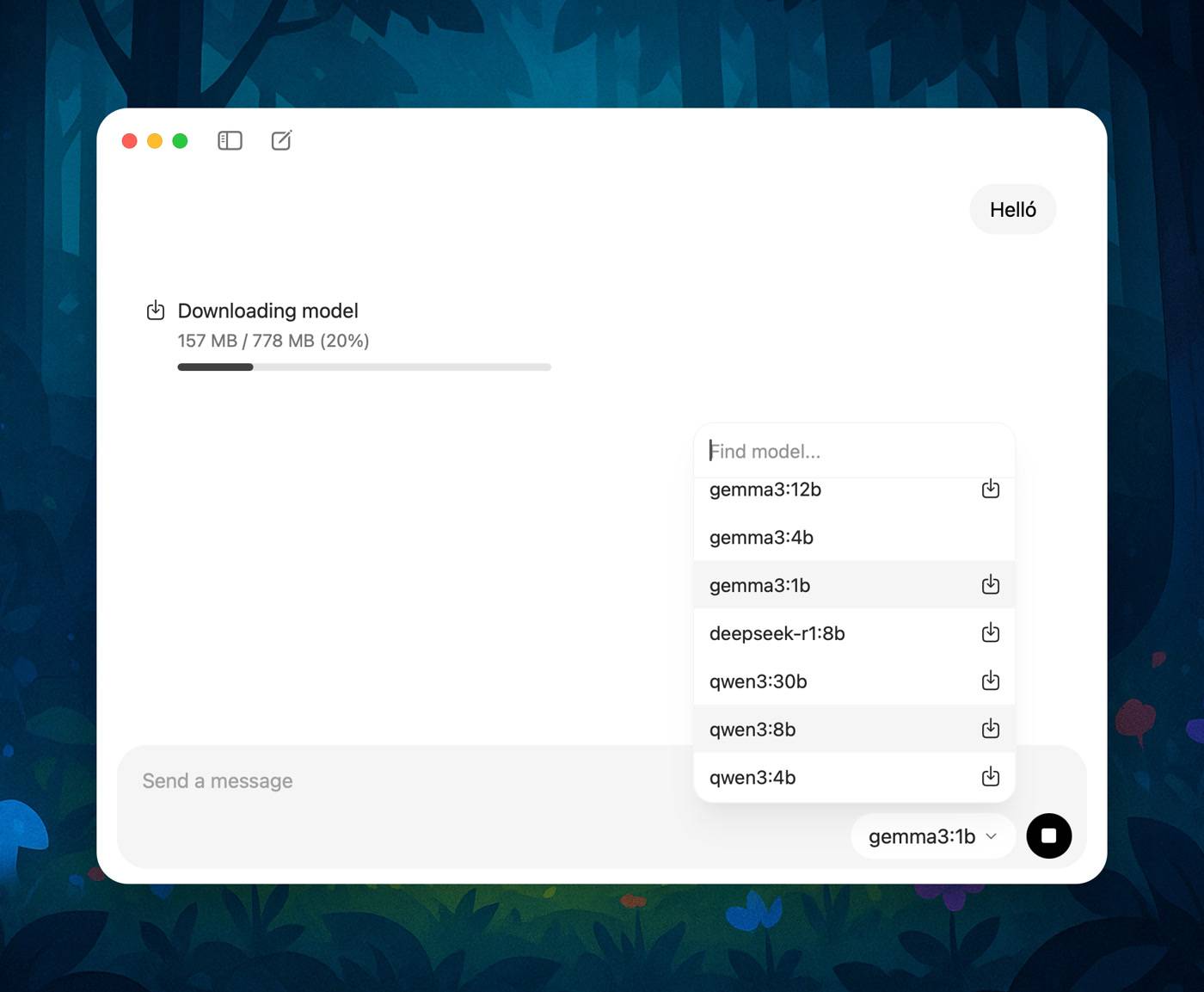
A modellek letöltése – ami persze szintén megoldható a hagyományos parancssoros megoldással is – sokkal egyszerűbb lett, immár elég kiválasztani a kívánt modell nevét a program felületén, s ha még nincs letöltve, a kis letöltés ikonra kattintva a neve mellett – majd egy tetszőleges kezdő promptot beírva – máris letölthetjük azt, ha pedig már a gépen van, rögtön használhatjuk is a kiválasztás után.
Az új felület mellett, amely amúgy a fájlok használatát is jelentősen egyszerűsíti, akad azért még más izgalmas újítást is az Ollamában: nevezetesen 10-30%-os teljesítménynövekedésre van esélyünk több GPU használatakor, illetve a Gemma3n és hasonló modellek akár kétszer, háromszor is gyorsabbak lehetnek, mint a korábbi Ollama verziókkal voltak. Így aztán mostantól jó eséllyel az Ollama lehet a legegyszerűbb módja annak, ha egyszerűen és gyorsan használható módon szeretnénk beüzemelni az offline AI modelleket a számítógépünkön, amihez persze továbbra is javasolt a 8, de inkább 16 GB fölötti RAM mennyiség és az erős CPU/GPU teljesítmény.
Ollama Turbo: előfizetéses extrák és új OpenAI modellek
Akad még egy érdekes újítás az Ollama új változatában a fentiek mellett. Ez pedig nem más, mint hogy mostantól él az Ollama Turbo is, amely a programon belül teszi lehetővé, hogy csak offline, a helyi gépen érjünk el nyílt forráskódú AI megoldásokat, hanem használhassunk erre a célra bivalyerős távolis szervereket is. A magánszféra védelme és az adatbiztonság itt is kiemelt szerephez jut, viszont az előfizetésért cserébe tudunk webes keresést is beállítani a csevegésekhez, illetve olyan MI eszközöket is használni, mint az OpenAI vadinatúj gpt-oss-120b és gpt-oss-20b modelljei. Utóbbi persze egy erősebb otthoni hardveren is beüzemelhető akár offline is, de azért jóval gyorsabb a Turbo móddal használva, a 120b verzió pedig elég egyértelműen szerverért kiált a mérete miatt.
Az Ollama Turbo tehát egy új módszer a nyílt modellek futtatására adatközpont-szintű hardverek használatával. Mivel sok új modell túl nagy ahhoz, hogy a széles körben elérhető GPU-kkal használhassuk őket – vagy nagyon lassan futnak ilyen esetben -, az ez lehetőséget biztosít e modellek gyors futtatására az Ollama alkalmazás, a CLI és az API használatával. E energiaspórolás szempontjából is hasznos lehet, hiszen így nem a gépünket terheljük a modellek használatával.

{kind=link}